研究过后的东西总要写出来看看
0x00.缘由
QQ 空间的说说数据对于我来说还是很重要的,因为我这个人平常喜欢在空间发东西。奈何空间的搜索功能实在是太鸡肋了,明明有的说说就是搜不出来,再加上对此比较感兴趣有可能之后要爬取别人的,况且网上也有很多实例(当然肯定不能拿过来就用),本着对自己负责的态度开始了研究。
0x01.一些小 Tips
为什么要放在这里说,因为有必要提前说明一些东西(废话)……
- 空间数据的来源:a:
PC版,b:M版,c:手机QQ版,d:手机APP版。目前只想到了这四种,最后两种需要配置抓包环境(HTTPS什么的),但是抓包的结论是Fiddler抓不到,所以怀疑走的是TCP/UDP,这里暂时先放下不去细探索,我们先看前两种; - 如何存储数据,建立这篇文章的
.md文件的时候,我把它放在了crawler文件夹下,也就是归于爬虫一类,当然URL里也能体现出来。除了这篇文章,目录下有且仅有一个文件:analysis-bilibili-views.md,那篇文章的数据存储方式采用了SQlite,算是上古时期我存储数据的方式,同一阶段的bilibili_user_info爬虫(没发文章,仅私下)也采用了这种方法(因为那时候连MySQL都还没有接触……),存数据的时候不能多线程,否则会遇到database is locked,不过当时b的api也已经开始限速了,所以也没用上多线程,后来看来MySQL只后也没有换成它。当初看上它的一个原因是数据库就一文件方便传送,我是在OpenShift平台,当时注册了俩账号,一个免费账号最多有 3 个应用,每个应用都相当于一台VPS,即相当一 6 台小鸡。虽然没有root权限但是也非常爽了,当然最近升级到V3版本不能这么用了,我的单线程爬虫程序就是部署在那上面的,爬完之后直接FTP把*.db传回本地,后来的数据合并确实苦了一阵子,速度是在是太慢了(其实是我文件比较大一个文件有几百兆了)。对了,生成 bilibili 你的名字告白关键词词云这篇文章里存储数据的方式是爬取数据之后发送到腾讯云服务器的MySQL数据库之中,因为接口没有限速,所以爬虫采用了多线程保证速度,没有用SQlite。说了这么多发现跑题了,本来最初也是决定用MySQL的后来才了解到MySQL是“关系型”数据库,而还有一种数据库叫做“文档型”数据库——MongoDB,早闻Python+MongoDB大法好,不过一直没有细研究,又想起之前书签里存的MongoDB Atlas,想着爬完数据传到云端去,结果被数据传不进去坑了一阵,所以干脆搭在本地吧。不试不知道,一试吓一跳!MongoDB插入数据的方式是如此的简单,想起之前写MySQL插入语句的时候,实在是太累了,如下图……而且插入的速度比MySQL不知道要快多少倍……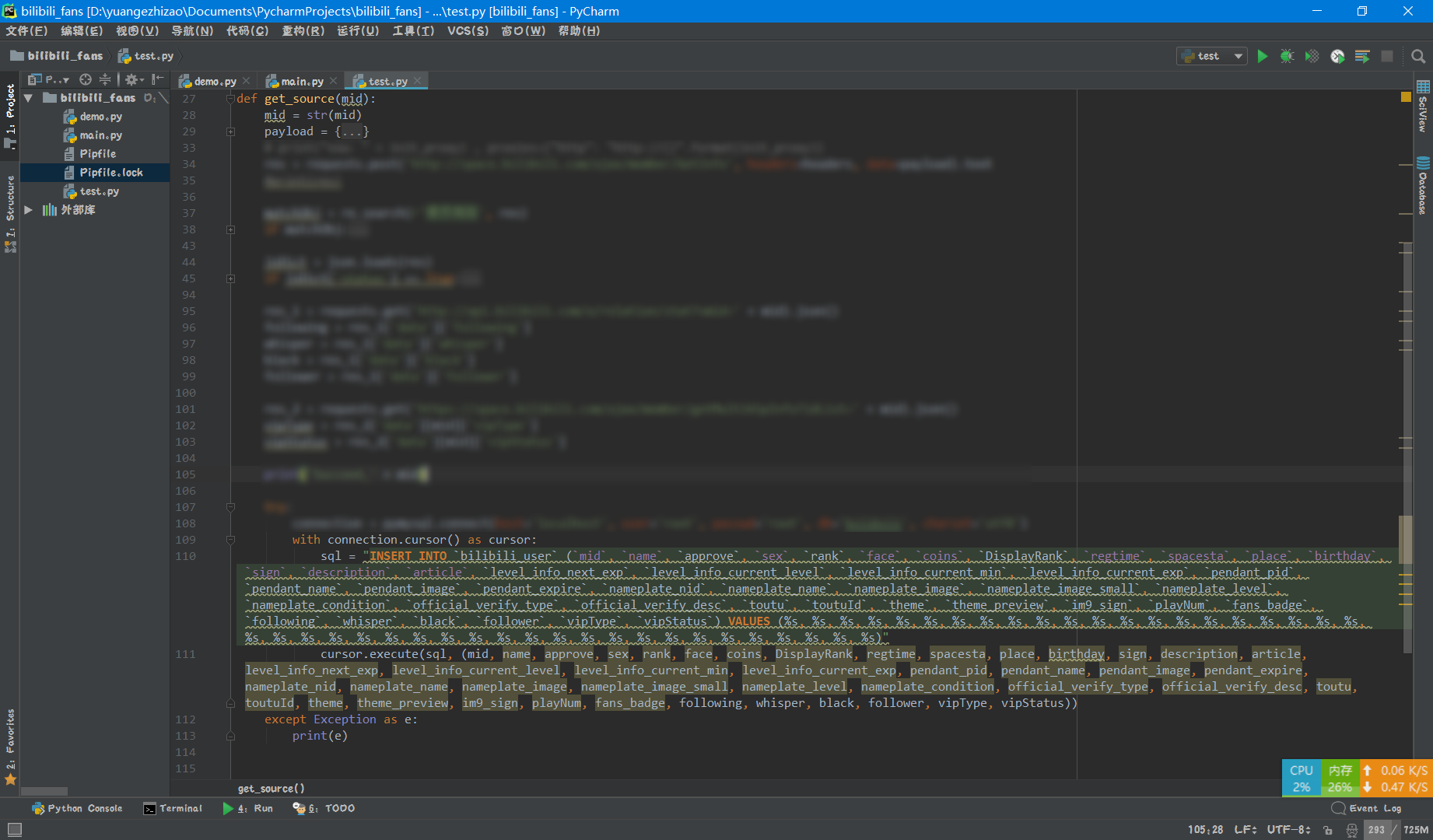 多到恐怖的 SQL
多到恐怖的 SQL
之后简单看了“文档型”数据库的介绍,哇……我为什么没有早点发现你啊,欲哭无泪……妈妈再也不用担心我取得的数据突然没有某个字段导致无法插入而在代码里使用try……except……包裹异常或者采用if 'regtime' in jsDict.keys() else 'HIDDEN'这种麻烦的方式了……
综上所述,本次爬虫采用的方法是原始数据保存至MongoDB,之后在看情况考虑处理数据的时候要不要用MySQL; - 有时候会遇到爬虫就是莫名爬不到的玄学问题,代码逻辑又觉得没有什么问题,这时候不妨先放下,在数据量小的时候,比如我某同学只有
24条,我直接把返回的json存到文本文档里,再导入MongoDB,这样也算是一种临时的解决方法; - 登录。我这么懒自然是不会看登录了,个人觉得完全没有必要,直接把登录号的
cookies放到程序里不就好了嘛,为什么要去研究那么复杂的问题(想都可以想到会很复杂),况且也不是要爬遍全网,所以没有必要去研究这个。 - 好像没有了……emmm打字打得手有些酸了……
0x02.接口地址(M 版)
从自己的空间的主页的好友里进入别人的空间,数据来自:
1
https://mobile.qzone.qq.com/combo?qzonetoken=< 你的 qzonetoken >&g_tk=< 你的 g_tk >&hostuin=< 对方 QQ 号码 >&action=1&g_f=&refresh_type=1&res_type=2&format=json
 空间首页
空间首页说说数据就在
vFeeds里面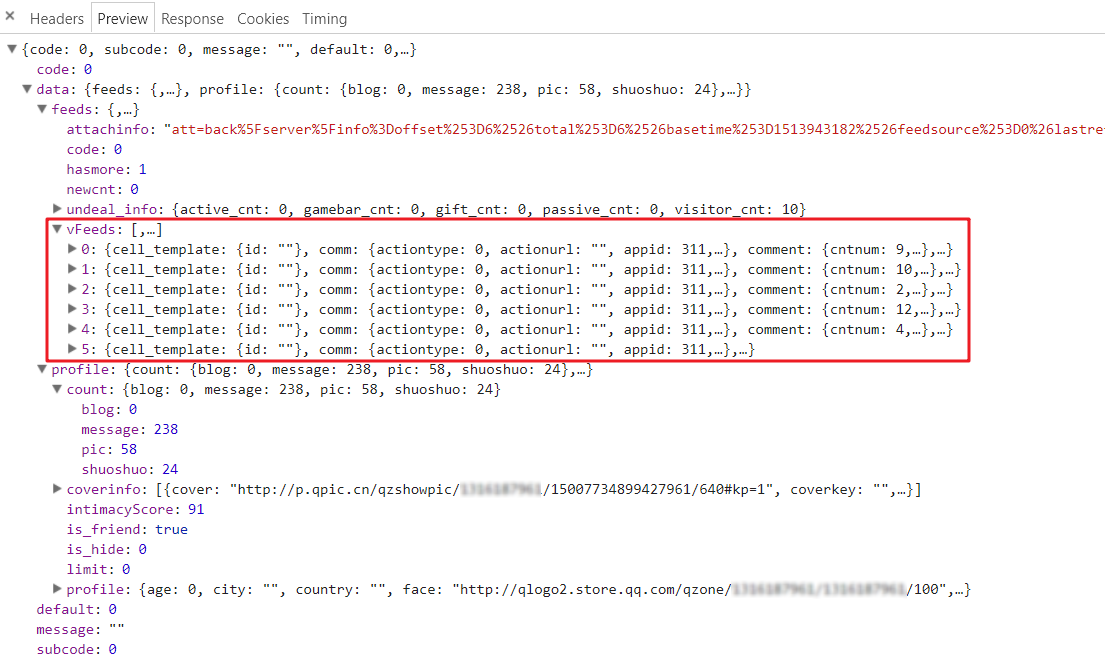 返回数据
返回数据
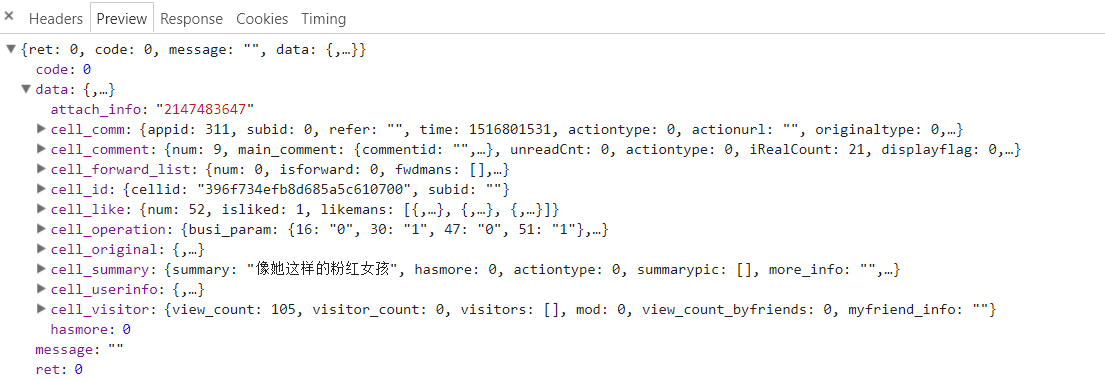
数据太大占版面,这里就贴一张图,个人比较关心的几个字段也都标好了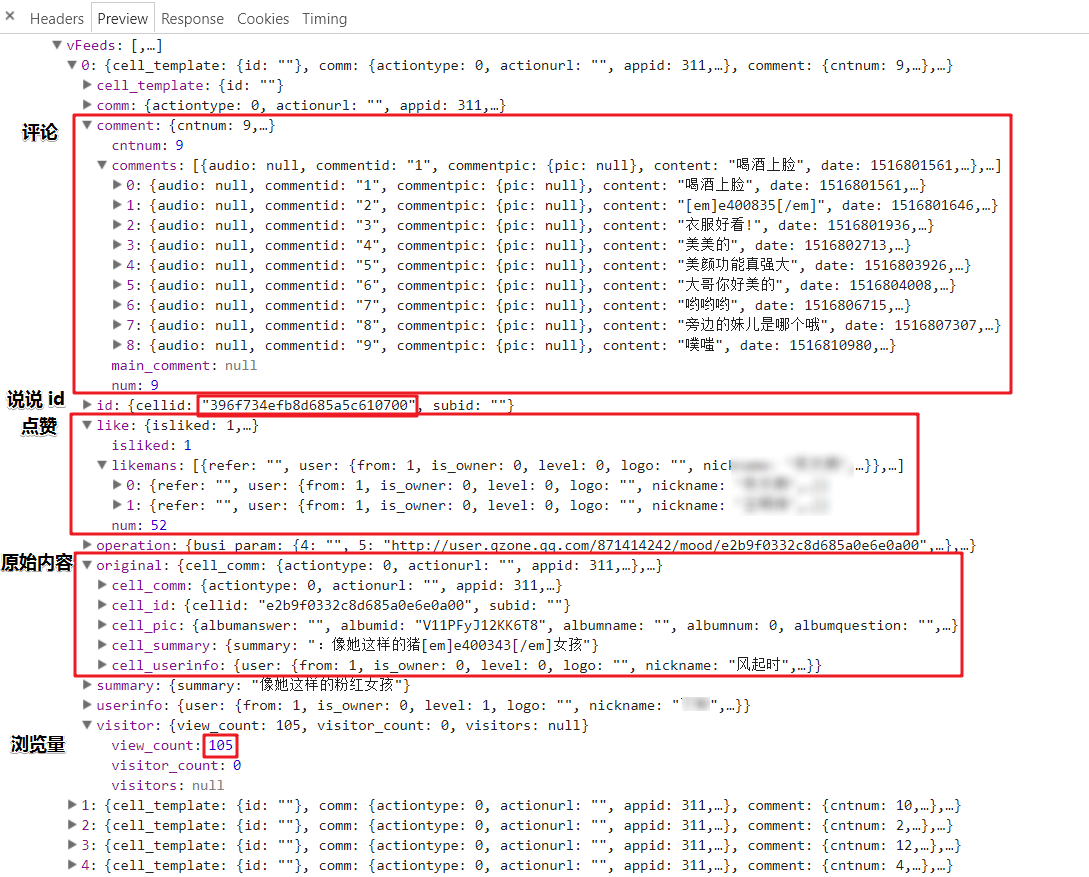 0
0但是上述只有 5 条,我们需要获取更多的说说就需要用到
attachinfo了。
下滑到页面底部,页面会自动加载,请求里用上了第一次返回的attachinfo,当然又返回了新的attachinfo供下次请求,所以说只要遍历就可以了,这就是本爬虫的核心点。
其实最开始我获取的是空间首页(第一张图)的“说说”里面的内容,数据是之前爬的,今天才发现评论和原始转发居然不全,根本没有渲染原始转发内容,如图所示。经尝试,这里的
count最大可以加到40……1
https://mobile.qzone.qq.com/list?qzonetoken=< 你的 qzonetoken >&g_tk=< 你的 g_tk >&format=json&list_type=shuoshuo&action=0&res_uin=< 对方 QQ 号码 >&count=10
详细接口,具体的细节不展开了
1
https://h5.qzone.qq.com/webapp/json/mqzone_detail/shuoshuo?qzonetoken=< 你的 qzonetoken >&g_tk=< 你的 g_tk >&appid=311&uin=< 对方 QQ 号码 >&count=20&refresh_type=31&cellid=< 说说 id >&subid=&busi_param=&format=json
0x03.思路分析
获取到全部cellid再去请求详细接口存库即可(又是废话)……
0x04.代码
略(还在整理之中……)
0x05.后记
从2018-2-3 19:22:03写到2018-2-3 21:41:57,期间没喝一口水,没动位置,我真是……emmm……
